My First Co-Op Research Project
During my first co-op term, I worked on a research project to develop a machine learning model to detect heart murmurs in audio recordings of heartbeats. The project was a great learning experience for me as I was able to learn a lot about machine learning and audio processing. There was a lot of challenges with this project and I had to be very analytical and creative to solve them. One of the most challenging aspects of this project was the lack of data.
How to even run a machine learning model on audio data?
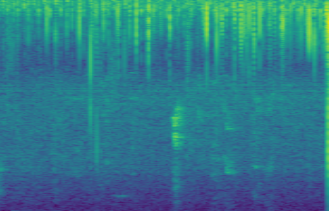
I had to learn a lot about audio processing and how to convert audio data into a format that could be used by a machine learning model. I was able to use the Librosa library to convert the audio data into a spectrogram. I then used the spectrogram as the input to a convolutional neural network. I actually came up with this idea myself and only later found out that this is what was done on some other audio processing machine learning models.
Generating More Data
One of the biggest challenges with this project was the lack of data. I was provided with a small dataset of audio files and a CSV file that mapped the audio files to the diagnosis, as well as other information such as the age and location of recording. To generate more data, I first converted the audio files into spectrograms and then used data augmentation to generate more data I did this by sliding the spectrogram along the time axis and adding some random noise to the spectrogram. This was a great learning experience for me as I was able to learn a lot about data augmentation and how to use it to generate more data.
How I built the model
I love using Tensorflow for building neural networks. I find that it has a good balance of ease of use and flexibility. When I just need to experiment and develop rapidly I can use Keras, but when I need to do something more complex I can use the lower level Tensorflow API. I used the Keras API to build the model. But I used the Tensorflow API to build the data augmentation pipeline. As well I also built the data input pipeline using the Tensorflow API to achieve maximum performance. When I build a model, I always find that it’s more of an art than a science. Since I’ve built a lot of models, I have a good intuition for what works and what doesn’t. I start by slowly building up the model, first with convolution layers and then adding pooling layers. I then add some fully connected layers and then finally the output layer. I then train the model and see how it performs. If it’s not performing well, I’ll try adding more layers or changing the learning rate. I also like to use the Tensorboard to visualize the training process and see how the model is performing.
Finding Issues
One of the biggest things I have learnt with my experience working on neural networks is that you can often spot what is going wrong just by looking at the data. Here are some of the things I look for and how I fix them:
-
Overfitting: If the model is performing well on the training set but not on the test set, then the model is overfitting. This means that the model is learning the training set too well and is not generalizing to the test set. To fix this, I can add more data, or use data augmentation to generate more data. I can also use dropout layers to remove some data to prevent the model from learning the training set too well.
-
Underfitting: If the model is not performing well on the training set, then the model is underfitting. This means that the model is not learning the training set well enough. To fix this, I can add more layers to the model or change the learning rate.
-
Data Issues: Sometimes the data itself is the issue. If their is no correlation between the input and the output, then the model will not be able to learn anything. I can fix this by looking at the data and seeing if there is any correlation between the input and the output. If there is no correlation, then I can try to find a different dataset.
-
Performance Issues: Sometimes the model is just not performing well. If it is taking hours to train there is some performance issue. This could be due to the model architecture or the data. I was fortunate enough in this project to have access to one of the UBC servers with a NVIDIA Tesla V100. This allowed me to train the model on a GPU and achieve maximum performance. It could also be due to the next issue.
-
Input Bottlenecks: Sometimes the input pipeline can be the bottleneck this was the case with this project, you can spot this by checking the utilization of the GPU if it is below 100% it is bottlenecked. To fix this, I used the Tensorflow API to build a high performance input pipeline that could feed the data to the model as fast as possible. It used multi-threading and prefetching to achieve maximum performance. This way I could generate the spectrograms and augment the data on the fly and feed it to the model as fast as possible.
The Final Model
The final model was a convolutional neural network that took in a spectrogram as input and outputted a diagnosis. I was able to achieve a somewhat decent accuracy of on the test set. However, there was issues with overfitting as the model was trained on a small dataset. If I was to continue with this project, I would look into augmenting the audio files themselves and not the resulting spectrograms.
Software Utilized
Comments (...)
Loading comments...
Leave a Comment
Could not post comment. Please check your inputs.